Theses
There are some specificities of how the bachelor/master thesis works in our group, mainly:
- the students are an integral part of our group, i.e. participate in the online chat and in the bi-weekly online group meetings (~1 hour Wednesdays) and online standups (10 min. Monday and Friday)
- the master thesis usually takes about 6 months (it is planned for about 20-24 weeks)
- once a week the student meets with the mentor (usually a PhD student or postdoc from our group), and keeps a meeting protocol (open questions, next to-dos, etc.)
- each student presents the results of the work at the group meeting, typically one intermediate presentation (after about 3 months, 10-15 min long, to get feedback), and one final presentation (25-30 min)
- the working language of our group is English, since most of the scientists are from abroad. That means, the weekly meetings with the mentor are usually in English, and the presentations to the team as well. Ideally, the work is also written in English, so that the students can also get regular feedback from the mentor while writing.
If you are interested in doing your bachelor’s or master’s thesis or a study project with us, don’t hesitate to contact either us via thesis.caisa@uni-bonn.de or directly the researcher listed on the team webpage. You can find there the areas of interest under the page of each researcher. Please send your CV, transcript of records, and links to any relevant software projects you worked on, if applicable.
Note: New thesis for the semester are in preparation and will be updated soon. In addition, if you have some research direction in mind, feel free to contact us.
Open Theses Topics
In the study of LLMs robustness, we need a model to verify the shift in the linguistic style of the LLM output. The only temporal model is the tempoBERT which has been trained on a dataset that consists of 4 decades of consecutive events. However, the problem with this model is that it’s highly unlikely to see linguistic shift in these four decades since they’re so close. And what the model might model could be biased towards events rather than linguistic variation. As a result, there’s a need for a model that can differentiate linguistic styles from each other. Hence, enter the real tempoBERT. The model will be trained on the Helsinki corpus of english texts which covers 3 phases of evolution in English language, namely Old, Middle, Early modern,
Contact Akbar Karimi.
With SHROOM we adopt a post hoc setting, where models have already been trained and outputs already produced. Participants will be asked to perform binary classification to identify cases of fluent overgeneration hallucinations in two different setups, model-aware and model-agnostic tracks. That is, participants must detect grammatically sound outputs which contain incorrect or unsupported semantic information, inconsistent with the source input, with or without having access to the model that produced the output. To that end, we will provide participants with a collection of checkpoints, inputs, references and outputs of systems covering three different NLG tasks like definition modeling (DM), machine translation (MT) and paraphrase generation (PG), trained with varying degrees of accuracy. The development set will provide binary annotations from at least five different annotators and a majority vote gold label.
Contact Akbar Karimi.
Consider, for instance, a scenario where one anticipates a 30% rise in stock prices versus a 3% rise. This nuance plays a pivotal role in fine-grained sentiment analysis (SemEval-2017 Task 5), as the former implies a stronger sentiment than the latter. Similarly, in a legal context such as SemEval-2023 Task 6, the statement “Stealing 10 dollars” compared to “Stealing 100,000 dollars” could potentially lead to differing court judgments. Additionally, in the context of clinical inference (SemEval-2023 Task 7), a patient’s systolic blood pressure reading of 119 versus 121 could convey contrasting implications. These examples underscore the significance of understanding numerical data in text and hint at a potential research direction that could improve performance in downstream tasks.
Contact Akbar Karimi.
Large language models (LLMs) are becoming mainstream and easily accessible, ushering in an explosion of machine-generated content over various channels, such as news, social media, question-answering forums, educational, and even academic contexts. Recent LLMs, such as ChatGPT and GPT-4, generate remarkably fluent responses to a wide variety of user queries. The articulate nature of such generated texts makes LLMs attractive for replacing human labor in many scenarios. However, this has also resulted in concerns regarding their potential misuse, such as spreading misinformation and causing disruptions in the education system. Since humans perform only slightly better than chance when classifying machine-generated vs. human-written text, there is a need to develop automatic systems to identify machine-generated text with the goal of mitigating its potential misuse.
Contact Akbar Karimi.
Data augmentation has been shown to help neural networks achieve a higher performance. However, not all the data points attribute the same to the performance of the models. Therefore, the aim is first to find some samples that contribute more than other samples to the model and then investigate the impact of data augmentation techniques when applied to various data points with different levels of contribution. For comparison, five widely used methods and datasets will be chosen to do experiments on.
Contact Akbar Karimi.
Goals would be, 1) develop & evaluate a model for cognitive distortion detection, prompt engineering approaches with chatgpt/gpt3 are possible routes. 2) use model to annotate my online support forum dataset, including deeper layers of conversational threads–evaluate 3) large-scale analysis of cognitive distortions at community-level and user-level, with rq’s such as, “what are trends in the kinds of cognitive distortions that are detectable by community i.e., by support-related concern/condition?”; “can we observe in longitudinal user data any changes in their cognitive distortions over long periods of time?”; “can we observe changes in the conversational threads–do some support providers help with reframing?” Would be a bonus if a student with psychology background would want to work on this.
Contact Allison Lahnala.
Ongoing Theses
Data augmentation has been shown to help neural networks achieve a higher performance. However, not all the data points attribute the same to the performance of the models. Therefore, the aim is first to find some samples that contribute more than other samples to the model and then investigate the impact of data augmentation techniques when applied to various data points with different levels of contribution. For comparison, five widely used methods and datasets will be chosen to do experiments on.
Data Augmentation (DA) is a way to increase the amount of training data for various applications. In DA, the goal is to perturb the input to make it slightly different but it has to be done in a way that keeps the label unchanged. While there have been numerous techniques for data augmentation in NLP, a study on the ability of these methods to preserve the input labels is lacking.

Argumentation and debating are the process of forming reasons that humans engage in. Sales negotiation is one of the conversational activities in which a buyer and a seller communicate reasons to arrive at a satisfactory selection amongst alternatives. In our lab, we have simulated the conversation between the customer and salesperson when they express their own opinions, not only to convince each other but also in order to learn from this negotiation. This preliminary work posed new challenges, such as how to improve the quality of the conversation by identifying stronger arguments. In this work, we are interested in addressing this challenge.
Finished Theses

We will work on building a customizable chatbot that can be set up to facilitate conversations about different subjects of interest. We will work with a bioethicist to construct a chatbot that can most effectively carry out this task. The bot will start with a set of rules and we will explore ways to expand upon it’s functionality which may involve the construction of classifiers using machine learning for the purpose of better understanding user values, interests, or questions. The interested student should have some experience with natural language processing and web development.

Receptiveness, or how willing someone is to thoughtfully engage with opposing views, is known to contribute to more successful conversational interactions. It is desirable to be able to identify this language automatically in order to analyze and build systems that use this type of language. A few receptiveness classifiers have been built using small existing datasets with receptiveness annotations. Using these, what Reddit communities do we hypothesize will be more or less receptive? What makes them receptive and how do they differ? Leveraging data from receptive communities, we can retrain a receptiveness classifier and evaluate it using annotated data. Additional experiments may include analysis of silver data; annotated by the agreement of multiple classifiers, and the resulting impact on building a new classifier.

Detecting fake news online is an important and timely issue. We are interested in investigating personal differences in how fake news is spread and developing models to detect fake news. Our group has collected data for this task and for thousands of Reddit users. This can be used to test models for personalization from embeddings, language models, priming, or others. These models have been not been used for many downstream applications and we are interested to find out if these can be more widely applied and how performance differs on downstream tasks. Each method requires a different amount of computation and memory so there are trade-offs to consider.
Receptive communication, or the willingness to engage thoughtfully with opposing views, is important to having cooperative, successful conversations. Our lab has obtained preliminary results on generating paraphrases of text input to create more receptive outputs. This preliminary work was performed on sentences and in this work we are interested in extending this to longer texts or documents. This adds additional challenges through the interplay of sentences conveying different information but sharing the same receptive style.
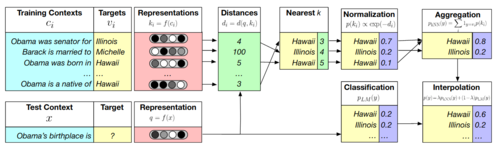
Language modeling forms the foundation of many language processing problems and involves predicting which words come next in a sequence. Recent work on kNN language models has shown improved perplexity by storing encodings of sentence contexts and retrieving similar contexts to alter the probability distribution when predicting the next token(Khandelwal et al. 2020). If we store not only the encoding, but also labeled stylistic attributes of a sentence (e.g.politeness, formality, toxicity), can we use this to control generated language to contain these attributes to higher or lower degrees while preserving fluency? How can these stored attributes and encodings be leveraged most effectively?

Sarcasm is a form of irony that occurs when there is a discrepancy between the literal meaning of an utterance and its intended meaning. Existing sarcasm detection systems focus on exploiting linguistic markers, context, or userlevel priors. However, social studies suggest that the relationship between the author and the audience can be equally relevant for the sarcasm usage and interpretation. New sarcasm dataset, focus in both types of sarcam, intended by the author, and perceived by the audience. We want to model different level of informations, text, author, and the audience, in order to explore the affect of these representations on different sarcasm types.
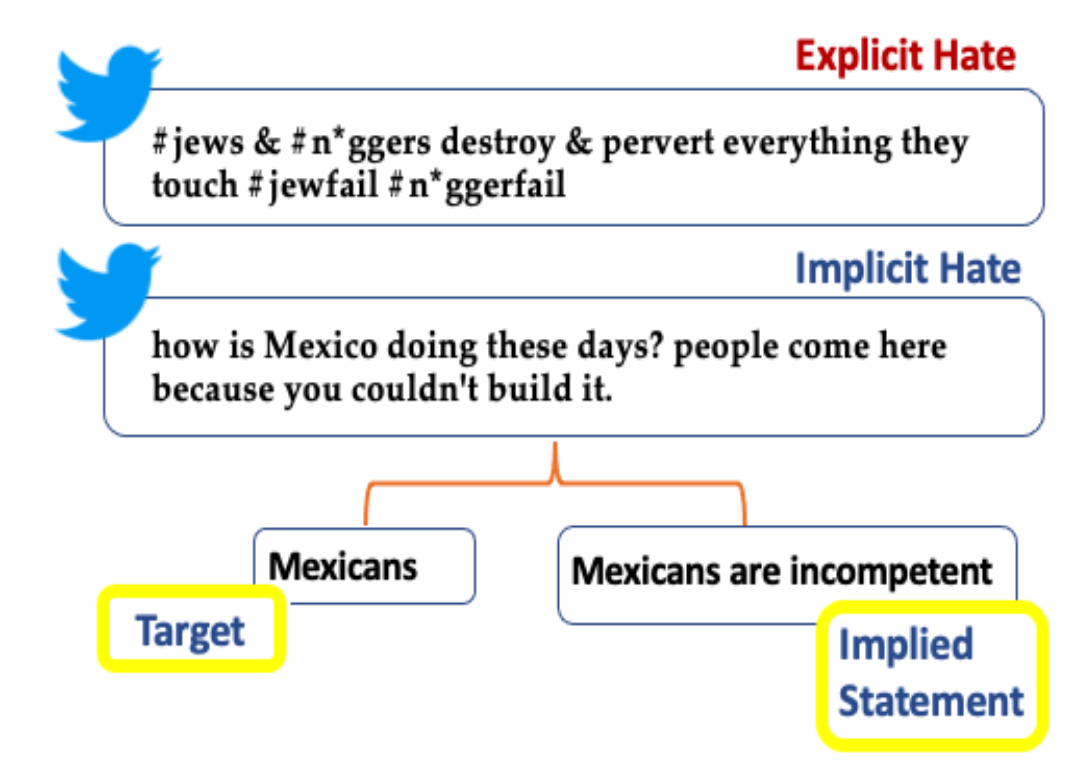
Implicit hate speech is defined by coded or indirect language that disparages a person or group on the basis of protected characteristics like race, gender, and cultural identity. Compared to explicit hate speech detection, implicit hate speech contains several challenges for the NLP models. One key challenge, is that implicit hate speech detection does not contain clear lexical flags like profanity or swear-words. In addition, sometimes it might also contain a “positive” sentiment due to linguistic phenomena like sarcasm, humour, euphism etc. In this thesis we would want to address the implicit versus explicit hate speech detection, by comparing the lexical cues used in the text, and also extending with information from a) the author of the hate text, and b) the targe of the hate text.

Recent works show that extreme partisans have a similar cognitive profile, showing that partisanship isn’t just a matter of political orientation, but a matter of intensity of one’s beliefs. Similarly, when a person expresses their opinion towards a specific socio-political issue, they can be dogmatic or receptive. Based on these works, we hypothesize that there are common linguistic, psychological and emotional attributes between extreme partisans and users who express their opinions strongly. In order to test our hypothesis, we wish to extract the linguistic attributes that are indicative of extreme or moderate partisanship - regardless of political direction. In turn, by processing the users’ posts on social media, we aim to automatically identify the author’s opinion intensity towards various socio-political issues in a zero-shot scenario.

Opinion detection aims to detect an author’s view towards a certain topic and has become a key component in everyday applications such as fake news detection and argumentation. While state-of-the-art deep learning models are ideal for this problem, they need lots of labeled training data that is often expensive to obtain. In order to reduce data collection costs, we can use few-shot-learning models which are specifically designed for learning with a very small amount of training data. Since most of our data comes from social media, we need a tool that can differentiate useful text from noisy, unopinionated posts. To this end, this thesis aims to develop an opinion detection model that can efficiently differentiate opinionated from non-opinionated text and is trained only on a small amount of data.

While social media platforms help to connect people worldwide and give access to enormous amounts of diverse information, they also foster an environment that promotes polarization. This occurs due to the fact that users show a tendency to consume content that aligns with their political leaning and join groups adhering to their beliefs. This phenomenon leads to the formation of segregated clusters, which are known as “echo chambers”. We aim to investigate the opinion formation between different user groups depending on the diversity of information they encounter through their social media usage. This analysis involves clusters formed based on (a) their political ideologies and (b) their tendency to disseminate false information.
Data augmentation techniques are used to generate additional, synthetic data using already existing data. While images can be augmented easily by transformations such as rotations or changes of the RGB channel without affecting the classification models, text augmentation is much more difficult because there are no universal rules for automatic textual data transformations that can be applied while maintaining the meaning of the text. Therefore this thesis aims to investigate various natural language generation techniques for paraphrasing opinionated text and evaluate the quality of the generated data on opinion detection.
This project will investigate the arguments people use to advocate that a book should be banned. This data may come from multiple sources, including social media, and data collected by other researchers. We will look to understand how these complaints relate to or reflect the actual content of books. Optionally, we could examine a broader context of banned books outside the USA. The interested student should have some experience with machine learning or natural language processing.