FACTOID - A New Dataset for Identifying Misinformation Spreaders and Political Bias
May 25, 2022
We are super excited to present our paper “FACTOID: A New Dataset for Identifying Misinformation Spreaders and Political Bias” from Flora Sakketou, Joan Plepi, Riccardo Cervero, Henri-Jacques Geiss, Paolo Rosso, Lucie Flek at LREC 2022.
In this work, we present a dataset called FACTOID: a user-level FACtuality and pOlitical bIas Dataset, containing 3.3M Reddit posts from 4,150 users for identifying misinformation spreaders and political bias.
You can download our dataset here.
TLDR;
This dataset is automatically annotated and covers the time period from January 2020 to April 2021 - that is the period before and right after the US presidential elections. In addition to the users’ binary labels regarding their misinformation spreading behavior, it also contains their fine-grained credibility level (very low to very high) and their political bias strength (extreme right to extreme left).
We provide benchmark methods for identifying misinformation spreaders by utilizing the social connections between the users along with their psycho-linguistic features. Through a qualitative analysis, we observed that detecting affective mental processes correlates negatively with right-biased users, and that the openness to experience factor is lower for those who spread fake news.
A more detailed explanation…
What is the focus of our work?
- Dissemination of online disinformation is growing
- Fact corrections frequently fail and might backfire.
- We address this issue at its origin and view the fake news detection task on a user level
- We explore misinformation spreading behavior together with political bias
Why is this dataset novel?
This is the first dataset, to the best of our knowledge, that:
- Captures both the long-term context of users’ historical posts and the interactions between them.
- Contains fine-grained labels of the factuality and political bias both on a post-level and a user-level.
Dataset
Terminology
The term misinformation in our paper is used specifically in the context of politics as an umbrella term that covers:
- misinformation: any news that is false or misleading but is not intended as such,
- disinformation: any false or misleading information that is spread with the specific intent of deception,
- hyperpartisan news: news that might not be entirely false, but they are phrased in a way that satisfies a specific political agenda and
- satirical news: any false content that has a humorous intent.
Data Collection and Annotation
We use mediabiasfactcheck.com as the main source for annotated news outlet domains, which offers fine-grained annotations for their factuality level and the political bias. To be considered a disinformation domain, the mediabiasfactcheck label has to be below or at Mixed factuality level or labeled as satire, while the real news domains have to be at least Mostly factual and between Right-Center and Left-Center political bias. In this way, we aggregated 1577 disinformation and 571 real news domains for our ground truth and post-level annotations.
Users were labeled as misinformation spreaders if they had at least two detected misinformation links in their post history, while for being real news spreaders they had to have no shared links from the misinformation list and at least one link posted from the factual news list.
We use an iterative and user-centric approach to collect the data:
- We start from a list of 65 subreddits concerning controversial political topics
- We performed the first iteration of the URL domain-based extraction to generate a list of Reddit misinformation and real news spreaders.
- We collected the complete histories of all the users in said list.
- We insert those threads into the database and extract a now larger list of misinformation and real news spreaders.
- We repeat this process until a sufficient amount of users is collected.
Data Labels
In addition to the binary separation of users into misinformation spreaders and real news spreaders, each user was annotated with the following factors by calculating the weighted average over a float mapping of the labels from mediabiasfactcheck.com, for a more fine-grained annotation:
- Factuality degree
- Political bias
- Science belief
- Satire degree
The Dataset
Dataset statistics
Here are some basic dataset statistics:
| Attribute | Statistic |
|---|---|
| Total number of crawled posts | 3.354.450 |
| Total number of users | 4150 |
| Total number of posts that contained news sources | 78387 |
| Average number of posts per misinformation spreader | 1240 |
| Average number of posts per real news spreader | 654 |
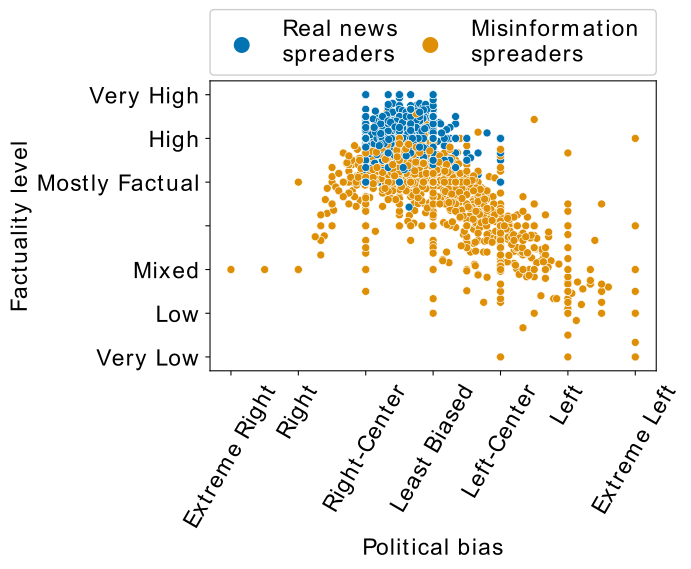
The political biases of the users can be looked at: 41.17% of the users that have left wing political bias are misinformation spreaders, while 58.82% of them are real news spreaders. 91.58% of the users that have right wing political bias are fake news spreaders, while only 8.41% of them are real news spreaders
Plot of the factuality factor over political bias of each user:
Number of fake news posts and real news posts associated with the political events from the table below:
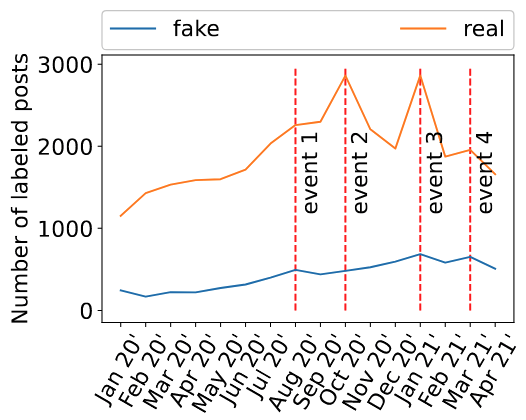
| Date | Event Description |
|---|---|
| Feb 5 | Trump is acquitted on the charges of abuse of power and obstruction of Congress. |
| Jul 11 | Mail-in votes are encouraged. |
| Jul 30 | Donald Trump threatens to postpone the election if it appears mail-in votes might go against him. (We regard this as if this had happened in August, since the effects of this political event would be still discussed during that month) |
| Aug 11 | Joe Biden chooses Senator Kamala Harris (D-CA) as his running mate (event 1) |
| Nov 3 | 2020 United States elections (event 2) |
| Jan 6 | US Capitol is attacked by supporters of Trump (event 3) |
| Feb 24 | Johnson & Johnson’s vaccine candidate receives emergency use authorization from the FDA (event 4) |
Methodology
We utilized the following user representations:
- UBERT - Average Sentence-BERT (SBERT) post embeddings per user to obtain their representations
- User2Vec - Optimizing the conditional probability of texts given the author.
- Psycho-linguistic - Using the Big Five Model and LIWC software to capture users’ personality traits and mental processes
and the following models:
- Support Vector Machine (SVM)
- Logistic Regression (LogReg)
- Random Forests (RnFor)
- Graph Attention Networks (GAT)
Results
We compare the graph-based results by using different initialization methods, namely UBERT, User2Vec, psycho-linguistic, concatenation of User2Vec and psycho-linguistic features, and random vectors. The following table provides a comparison of different user embeddings techniques for the GAT model on the fake news spreader detection task.
| Fake News Spreader Detection | |
|---|---|
| Model | F1 score |
| GAT + User2Vec (200) | 61.6% |
| GAT + UBERT (768) | 61.2% |
| GAT + Psycholing (83) | 53.6% |
| GAT + User2Vec + Psycholing (283) | 59.4% |
| GAT + Random (200) | 47.8% |
The following Table shows the F1 score of the baseline models for both the fake news spreader and political bias detection tasks. For the fake news spreader detection task, User2Vec consistently obtains significantly better results than UBERT, and achieves the best result with a Random Forest classifier. For the political bias identification task, we observe the reversed behavior. UBERT consistently obtains better results than User2Vec, and achieves the best result with SVM.
| Fake News Spreader | Political Bias | |||
|---|---|---|---|---|
| Model | UBERT | User2Vec | UBERT | User2Vec |
| SVM | 53.9% | 61.1% | 66.2% | 63.0% |
| LogReg | 58.6% | 59.8% | 64.7% | 62.8% |
| RnFor | 49.7% | 61.3% | 64.9% | 63.5% |
The following Table shows the ablative results of the psycho-linguistic features on the Reddit dataset for both political bias and fake news spreaders detection. For the fake news spreader identification task, the BFM encoding appears slightly more effective. Indeed, since personality regulates the behavior in real contexts, it is reasonable to assume it to be also influential within virtual communities. The dominant factor is here the openness to experience: as expected, in those who spread fake news, there is greater rejection or less curiosity towards ideas outside their belief system. Also, the schizotypy disorder appears relevant, consistent with previous empirical observations[^note1]. In general, psycho-linguistic features show a significantly higher effectiveness in distinguishing users on the basis of political bias. Most relevant mental process is the affective kind, which correlates negatively with the target class, suggesting that right-biased users tend to express fewer emotions such as anxiety, anger and sadness in the text.
| Fake News Spreader | Political Bias | |||||
|---|---|---|---|---|---|---|
| Model | LIWC | BFM | Both | LIWC | BFM | Both |
| SVM | 56.2% | 51.0% | 53.9% | 55.1% | 38.8% | 61.0% |
| LogReg | 58.3% | 55.1% | 58.3% | 63.6% | 51.5% | 63.9% |
| RnFor | 55.9% | 58.4% | 54.8% | 56.6% | 54.8% | 61.7% |
Conclusions
- We introduced FACTOID, a user-level factuality and political bias dataset
- The proposed dataset contains fine-grained scores about the users’ factuality and political bias
- We utilize different user representation techniques to classify them
- Graph modeling of the users using their social media activity
- Qualitative analysis of the impact of various psycho-linguistic features
[^note1] Buckels, E., Trapnell, P., Andjelovic, T., and Paulhus, D. (2018). Internet trolling and everyday sadism: Parallel effects on pain perception and moral judgment. Journal of Personality, 87, 04