LREC 2022 Investigating User Radicalization - A Novel Dataset for Identifying Fine-Grained Temporal Shifts in Opinion
April 08, 2022
We are very excited to present our all-female-author paper “Investigating User Radicalization - A Novel Dataset for Identifying Fine-Grained Temporal Shifts in Opinion” from Flora Sakketou, Allison Lahnala, Liane Vogel and Lucie Flek at LREC 2022.
In this work, we present a dataset called SPINOS1 (Subtle Polarity and INtensity Opinion Shifts), which contains 3.5k Reddit entries from 600 users for modeling opinion dynamics and detecting fine-grained stances.
TLDR;
The dataset includes a sufficient amount of stance polarity and intensity labels per user over time and within entire conversational threads, enabling the detection of subtle opinion fluctuations both in the long term and in the short term. All posts are manually annotated by non-experts and a significant portion of the data is also annotated by experts. In our paper, we provide a strategy for recruiting suitable non-experts and show that by following this strategy, the resulting annotations obtained from the majority vote of the non-experts are of comparable quality to the annotations of the experts.
We analyzed the stance evolution in long term and short term levels. When analyzing the stance evolution on a long term level, we observed that users change the polarity of their stance rather frequently, however most users express strong intensities for only one of the two poles (in favor or against). On a short term level, when analyzing the opinion fluctuations within conversational threads, we observe that there is usually only a change in intensity and rarely in the polarity, leading us to the conclusion that opinion change is expressed over time. In addition, we provide a comparison of language usage between users who tend to change their opinion frequently and users who are more stubborn, and also employ fine-grained stance detection baselines.
On to the long version then…
Why is this work important?
- Temporal data about user opinions is necessary in order to study the dynamics of radicalization and polarization.
- There is a significant lack of NLP data resources that enable such studies.
- Due to the lack of resources, the is also a lack of efficient, data-driven models that investigate the relationships between social media behaviors and opinion formation and fluctuation.
- By introducing this dataset, we attempt to bridge the gap between the theoretical sociopolitical approaches and NLP methodologies
Why is this dataset novel?
This is the first dataset, to the best of our knowledge, that provides:
- a sufficient amount of annotated user history which enables the investigation of opinion shifts both in the long-term but also within a conversation,
- both stance polarity and intensity annotations regarding a large range of sociopolitical issues.
Annotation
Annotation Labels and Guidelines
You can find here an example of the annotation template. The template contains the detailed annotation guidelines, the options given to the annotators and the survey they were asked to fill. Namely, the labels that could be assigned are: strongly against, somewhat against, somewhat in favor, strongly in favor and stance not inferrable.
In addition to the stance polarity and intensity labels, we also provide the following labels for each post:
-
Contextual information requirement. For every annotation, the annotators could optionally view the top-level post in the thread and/or the previous posts in the thread. This label indicates whether such information was needed for the annotation.
-
Stance explicitness. A label that indicates whether the stance of the author was explicitly stated or implied within the text.
-
Expression of sarcasm. A label that indicates that the content is sarcastic (only for the cases where a stance is assigned).
-
Uncertainty of assigned label. A label that indicates whether the annotators feel uncertain of their annotation (only for the cases where a stance is assigned).
Annotation Phases
The dataset was manually annotated by expert annotators and non-experts (NE) with Mechanical Turk.
-
First phase: In the first phase, three expert annotators annotated a small subset of posts. The expert annotators were trained on a small subset of posts, where they were able to ask questions and discuss opinions in case of disagreement.
-
Second phase: In the second phase, we introduce a two-step process in order to recruit the suitable annotators:
-
We introduce a relatively demanding qualification test to ensure that the NE annotators have a comprehensive understanding of the guidelines.
-
We compute the pairwise inter-annotator agreement between the experts (who passed the qualification test) and the non-experts, and select the NE annotators with the highest scores.
-
The Dataset
Dataset statistics
For each user, we collected statements that were posted on average over the course of 6 months and at most within 15 months. The posts were collected from April 2019 to July 2020.
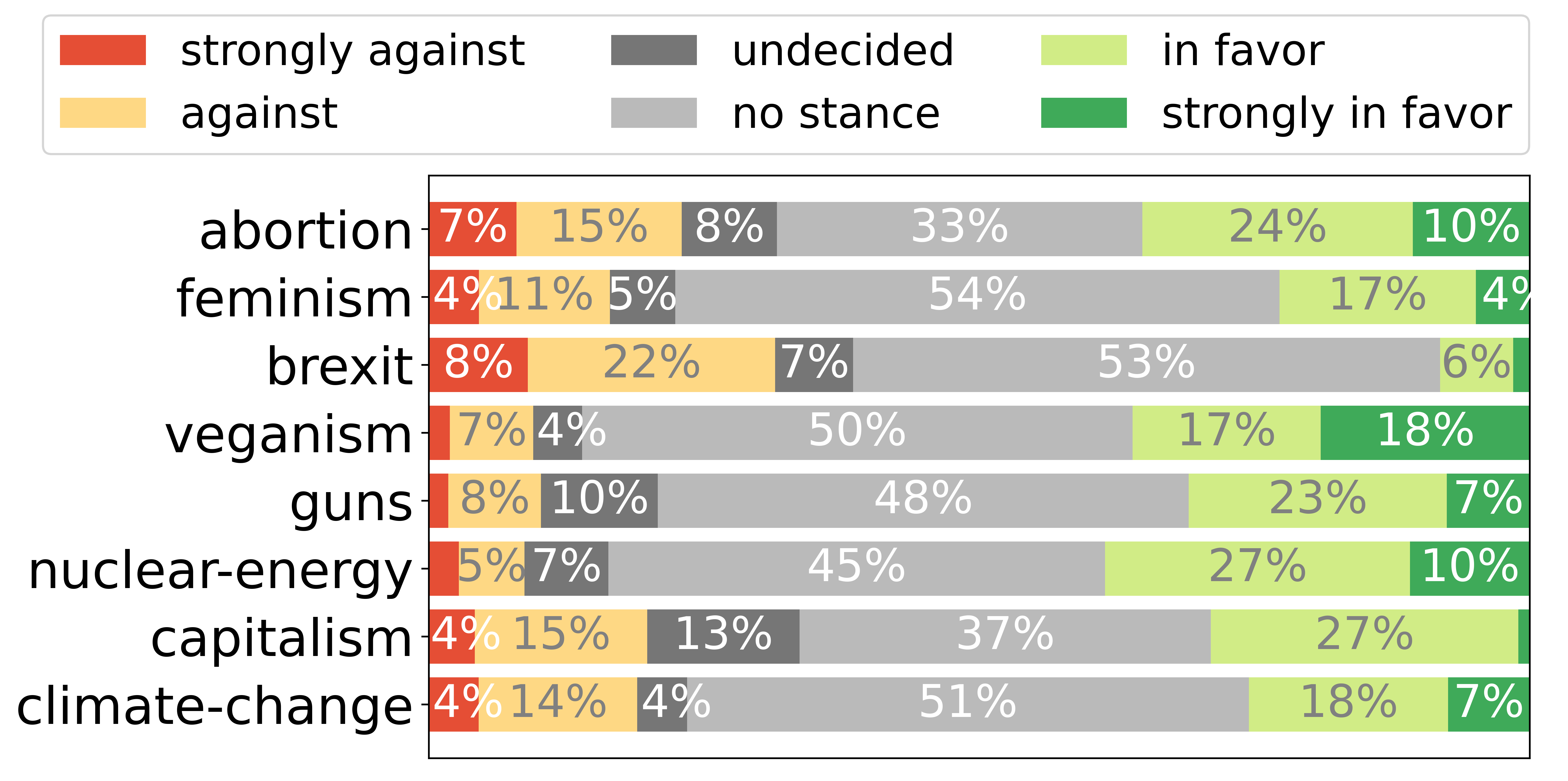
Our dataset includes the following topics: (1) abortion, (2) feminism, (3) brexit, (4) veganism/animal rights, (5) guns, (6) nuclear energy, (7) capitalism, and (8) climate change. This is the topic distribution in our dataset:

Here are some basic dataset statistics:
| Attribute | Statistic |
|---|---|
| Total number of annotated posts | 3526 |
| Total number of annotated posts by experts | 673 |
| Total number of annotated authors | 638 |
| Average number of posts per author | 5.53 |
| Number of annotated threads trees | 113 |
| Number of annotated thread branches | 547 |
| Number of posts in annotated thread trees | 1752 |
The final annotation labels are decided by the majority vote between at least three annotators. The undecided label was assigned in cases where the votes were equally distributed to each polarity and the non inferrable category. The stance distribution per topic can be looked at:
Annotator statistics
We compute the following inter-annotator agreements (Fleiss’ Kappa):
- Overall: Agreement on the overall five categories,
- Merged intensities: Agreement on the ability to identify the stance without considering the intensity by merging the weak and strong intensities (three categories),
- Stance existence: Agreement on whether there is an inferrable stance or not (two categories).
- Intensity: Agreement on the stance intensity, for the cases where the stance was inferrable (two categories).
- Polarity: Agreement on the stance polarity, for the cases where the stance was inferrable (two categories).
This figure shows the values of the inter-annotator agreements between non-experts for the first and second phases, the inter-annotator agreement between the experts and the inter-annotator agreement between the experts and the majority vote of the non-experts.
This shows that our recruiting strategy has a beneficial effect on the inter-annotator aggreement of the second phase, and, more importantly, that the majority vote of non-expert annotations are of comparable quality to the annotations obtained from the experts.
This figure shows the inter-annotator aggreements per topic for the second phase on the annotation process.
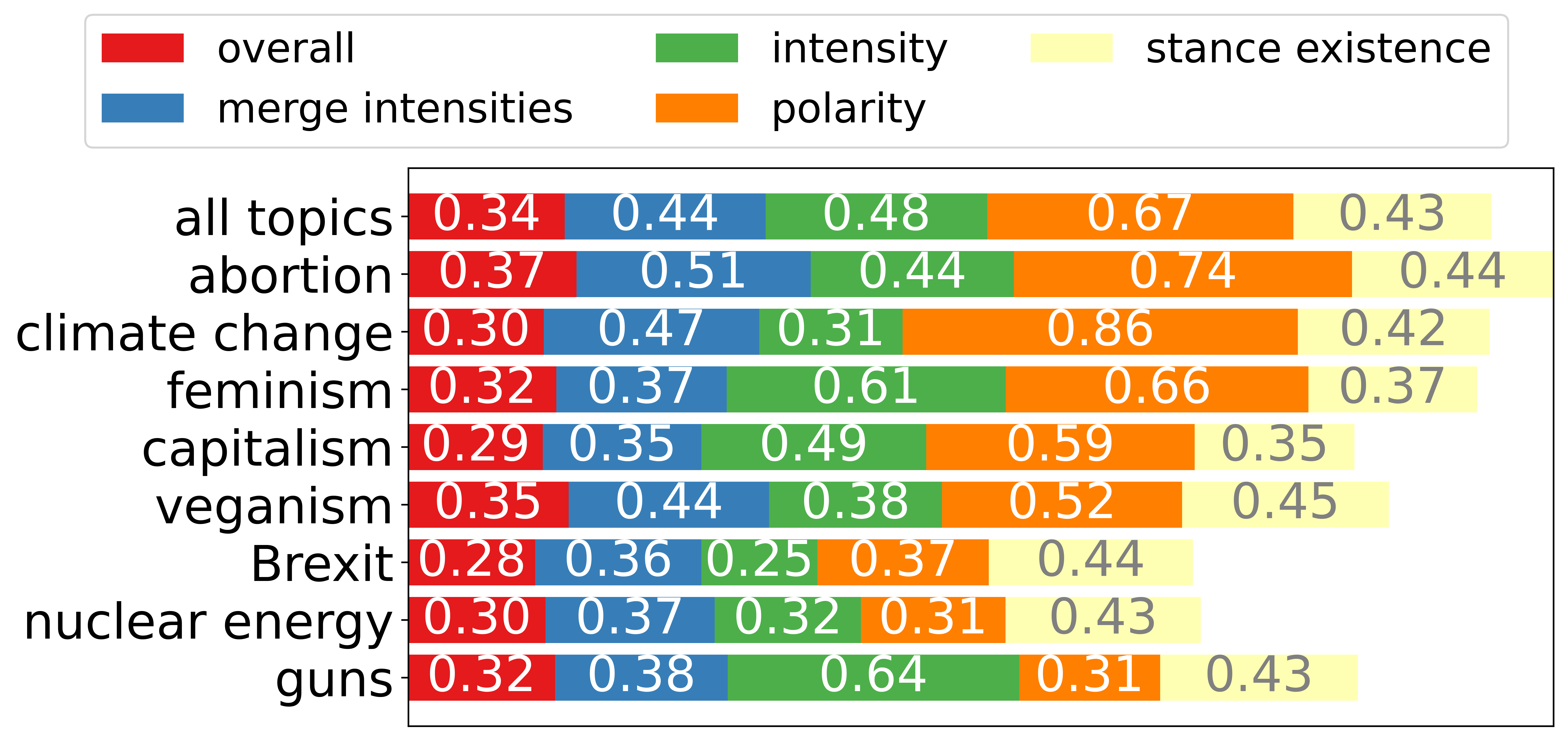
In cases such as Brexit, nuclear energy, and capitalism, we observed that there is a heavy use of terminology, which could explain the lower inter-annotator values than in everyday topics such as abortion and veganism.
Case Studies
User Stance Entropy
SPOILER ALERT: Opinion change happens gradually over longer periods of time, however changes in opinion intensity can be observed within a conversation.
This figure shows a selected sample of annotated posts from one specific user and how this user’s opinion changes over time regarding abortion. Each row represents a distinct user and, each block represents a post and that user’s stance towards a topic. On the y axis we show each user’s entropy.

We computed the user’s entropy as an indicator of opinion change; high entropy users tend to oscillate between different stances, while users with low entropy have a stable opinion polarity and might only change the intensity of their stance.
This figure shows the evolution of the opinionated users’ stances through time for the topic abortion. Each row represents a distinct user and each block represents a post and that user’s stance towards a topic. On the y axis we show each user’s entropy.

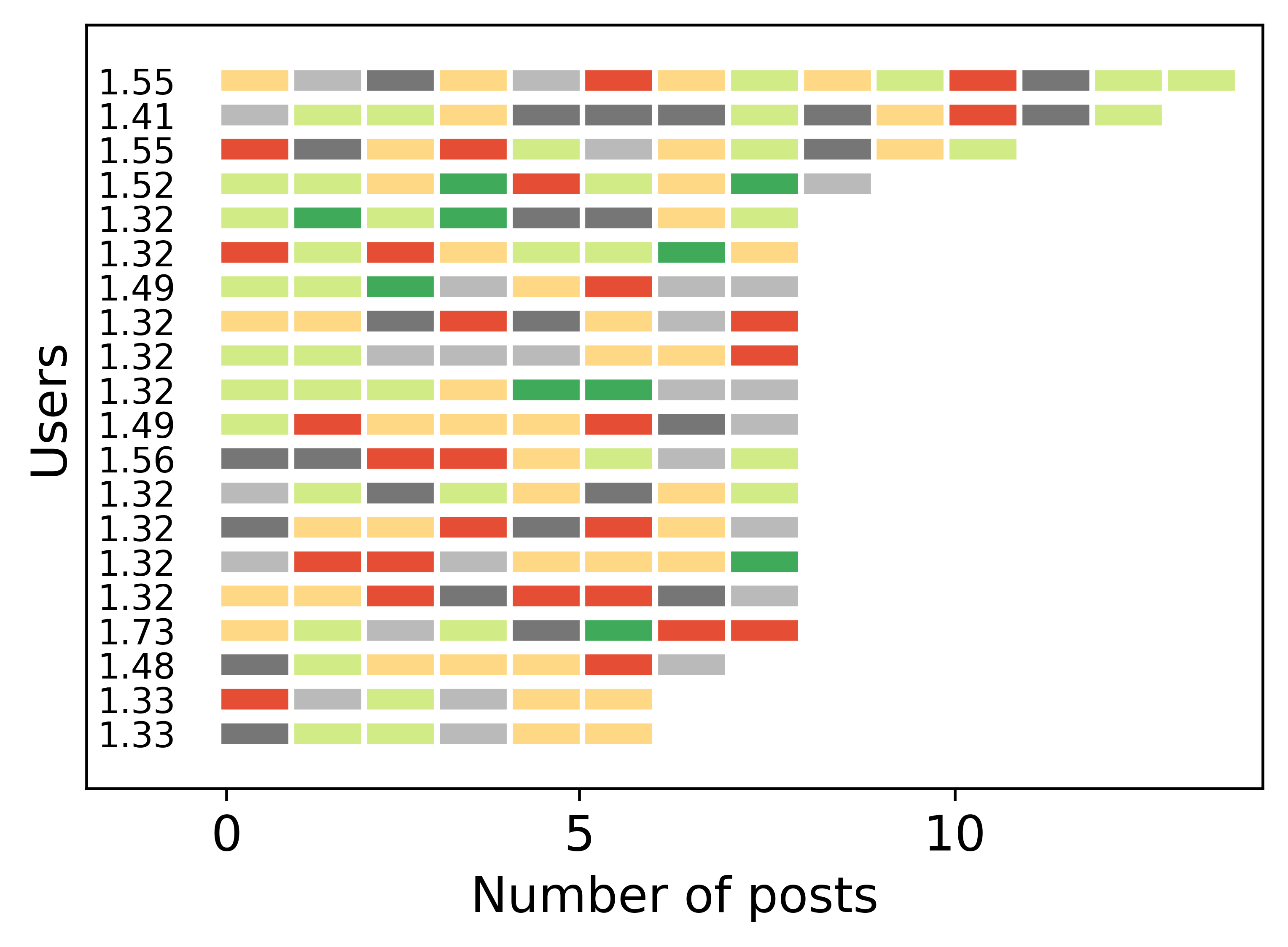
Most users change the polarity of their stance, however they rarely show strong intensities for both polarities. After further investigation, we observe vacillating attitudes in users with posting periods of over one month (similar patterns in opinion change are present for the rest of the topics).
This figure shows the evolution of the users’ stance within a thread.
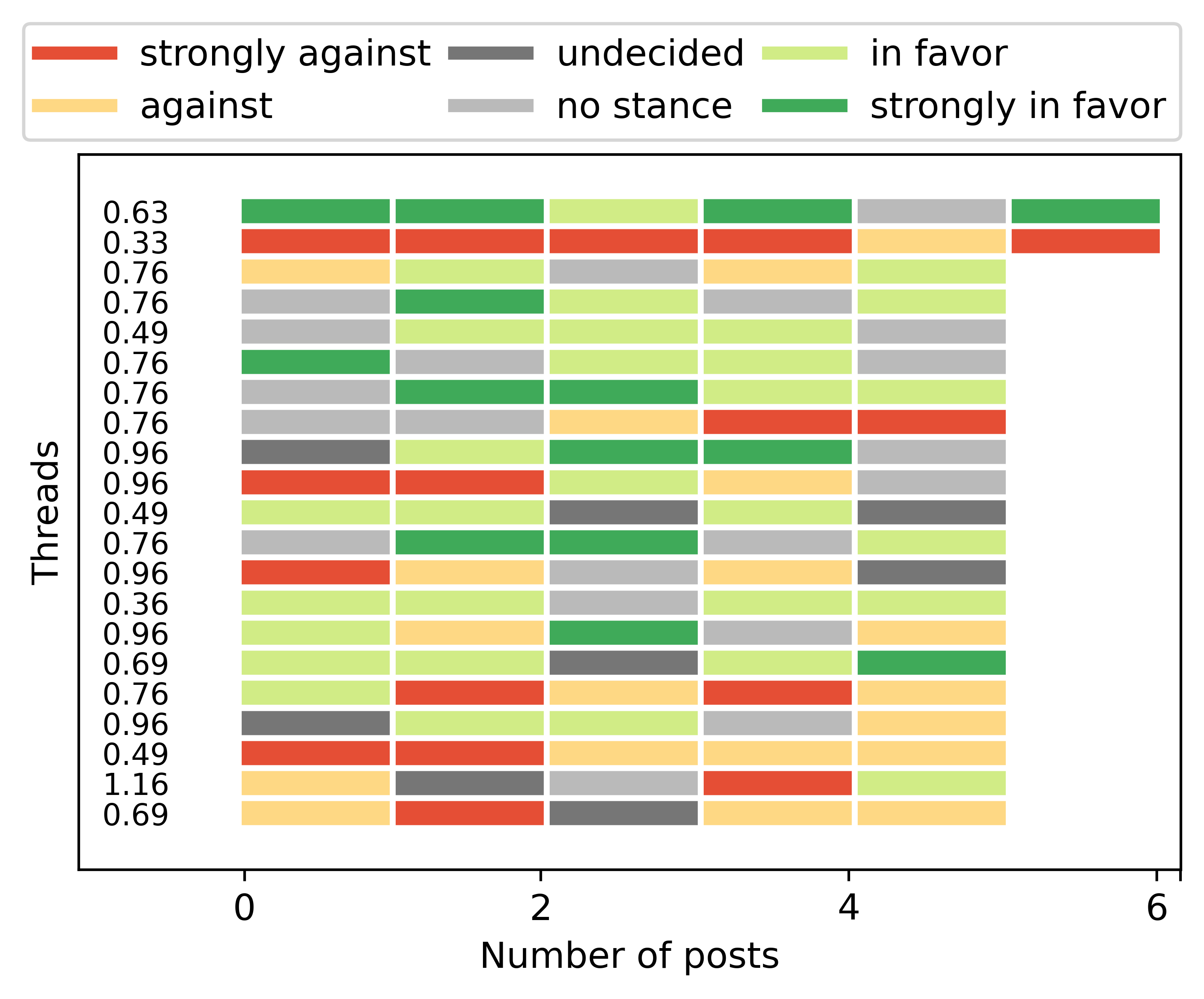
We can see that in most cases the users change their stance intensity and rarely their polarity, leading us to the conclusion that opinion change happens gradually over time or at least it is not immediately expressed within the conversation.
Stance Detection
We performed the following classification tasks:
- Has stance: binary classification of whether the post has a stance or the stance is not inferrable
- Intensity: binary classification of whether a post’s stance is weak or strong regardless of its polarity
- Polarity: three-class classification of the polarity (against/favor) or stance is not inferrable
- Fine-grained: four-class classification of the inferrable stances with intensities (i.e., strongly against, against, favor, strongly favor)
- All: five-class classification of the fine-grained stances, including stance not inferrable and excluding the posts from the ‘undecided’ class.
- All-maj: Same as ‘All’ but taking into account only the posts with majority agreement (at least two of three votes)
We evaluated several different n-gram models (up to trigrams) with Naive Bayes, Linear SVC, and Logistic Regression classifiers and a bert-based approach in a 10-fold setup. DISCLAIMER: We did not perform extensive experiments with varied parameters or feature engineering.
This figure shows the top performing models by weighted F1 score for each classification task.
| Task (# classes) | Top Model | Random Baseline | Majority Baseline |
|---|---|---|---|
| Has stance (2) | 0.660 | 0.510 | 0.365 |
| Intensity (2) | 0.652 | 0.594 | 0.609 |
| Polarity (3) | 0.495 | 0.344 | 0.198 |
| Fine-grained (4) | 0.373 | 0.307 | 0.258 |
| All (5) | 0.341 | 0.230 | 0.124 |
| All-maj (5) | 0.340 | 0.211 | 0.124 |
Though the models are capable of outperforming the majority baseline, their performances are low within reason, as they reflect the difficulty of the task experienced by the human annotators. If we consider, for instance, how much the model for the polarity three-class task improves over the majority class baseline broken down by topic, the topics with highest agreement also have the models with the most significant improvement. That is, the abortion and climate change topics have both the highest agreement and most significant improvement over the majority class, while capitalism and nuclear energy have much lower agreement and the model shows no significant improvement.
Take-aways
- We introduce a super cool and innovative dataset for detecting subtle opinion changes and fine-grained stances.
- The dataset contains a sufficient amount of stance polarities and intensities per user on various sociopolitical topics over time but also within entire conversational threads.
- We show that through our recruiting strategy, the resulting set of non-expert annotations is of comparable quality to that of the experts.
- However, we observe low inter-annotator agreement in topics with highly technical and scientific terminology.
- By analyzing the opinion fluctuations over a short and long periods of time, we conclude that opinion change is expressed over long periods of time.
- We provide baseline results for different setups, showing that this dataset offers a range of challenging tasks.
Future Work
- The users’ historical posts can be used to model their temporal behavior in order to predict subtle opinion shifts.
- Further investigateion regarding relationships between intensity persistence and temporal aspects of user behaviors. Such work could consider relations to real-world events, forum engagement activity, and linguistic changes.
- Does receptive language relate to opinion or intensity changes, or linguistic style matching in interactions between users with shared or opposite opinions.
- Investigate the potential relationship between the expression of various emotions and stance intensity.
-
Fun fact: SPINOS in Greek (σπίνος) means chaffinch. Interestingly, this name brings together some of the authors of the paper, since the first author is Greek, the second author is an aspirant birdwatcher and the third author’s surname means “bird” in German. ↩