Perspective Taking through Generating Responses to Conflict Situations
August 15, 2024
Despite the steadily increasing performance language models achieve on a wide variety of tasks, they continue to struggle with theory of mind, or the ability to understand the mental state of others. Language assists in the development of theory of mind, as it facilitates the exploration of mental states. This ability is central to much of human interaction and could provide many benefits for language models as well, as being able to foresee the reactions of others allows us to better decide which action to take next. This could help language models generate responses that are safer, in particular for healthcare applications, or more personalised, e.g. to sound more empathetic, or provide targeted explanations. These systems can generate responses that are not only relevant to the users queries but also reflect users personal style. Thereby creating a more engaging and customised interaction experience.
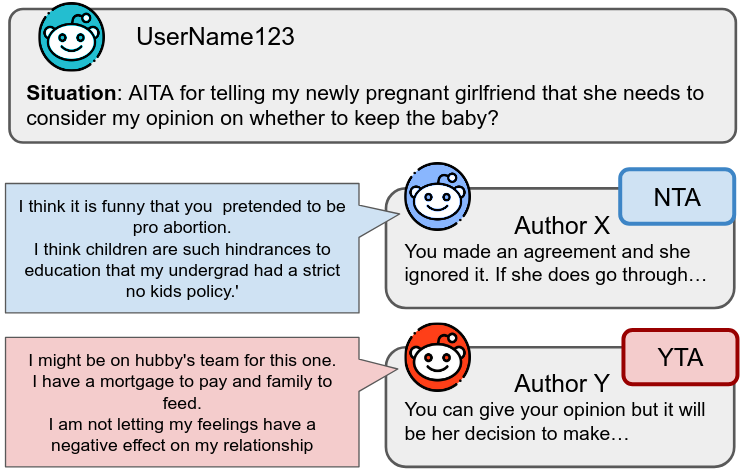
In fact, there is a growing interest in a perspectivist approach to many natural language processing (NLP) tasks, which emphasizes that there is no single ground truth. We construct a corpus to study perspective taking through generating responses to conflict situations. An example from our corpus can be found in Figure 1. We see a user asking if they did something wrong in a conversation with their girlfriend about whether or not to terminate a pregnancy. On the right, there are two responses from other users with different judgments of the situation (reasoning and verdict NTA/YTA). On the left, we see self-descriptive statements of each user. Author Y appears to be more family-oriented than Author X which may impact their judgement of the situation.
We focus on three research questions:
- RQ1: How should we evaluate perspective taking through the lens of NLG?
We develop a novel evaluation of by asking humans to rank the human response, model output, and a distractor human response, combining approaches from persona consistency. We find that previous consistency evaluation metrics are inadequate and proposed a human ranking evaluation that includes similar human responses. Additionally, we find that our generation model performed competitively with previous work on perspective classification.
- RQ2: Do tailored, user-contextualized architectures outperform large language models (LLMs) on this task?
We design two transformer architectures to embed personal context and find that our twin encoder approach outperforms LLMs. We compare tailored architectures to LLMs, including two novel methods, finding that our twin encoder architecture outperformed recent work, FlanT5 and Llama2 models.
- RQ3: What user information is most useful to model perspective taking?
Experiments with varied user context showed that self-disclosure statements semantically similar to the conflict situation were most useful.
Joan Plepi contributed to this article.