NAACL2024 was great!
July 04, 2024
Our group contributed with three works: (1) Scaling annotator modeling (2) group fairness preservation under differential privacy: https://lnkd.in/e8Kh4Y9n (3) modeling information spreader behavior
In (1), we argue that when annotation tasks are meant to encompass diversity, models shall not solely rely on the majority class label. We perform the first systematic study of the scalability of perspectivist annotator modeling methods, in which we explore tasks across 7 corpora and discuss relationships between corpus statistics and annotator model performance.
In (2), we train (𝜀,𝛿)-differentially private models with empirical risk minimization and group distributionally robust training objectives. We show that in the baseline setting under DP-SGD fairness decreases (disparity widens on between-group performance differences), however, we can mitigate this by using Group DRO optimization. In such robust setting, DP even reduces the between-group performance differences, which we explain by interpreting DP as regularization.
In (3), we show that detecting unreliable news spreading in Reddit and Twitter is more accurate when including behavioral patterns of the users.
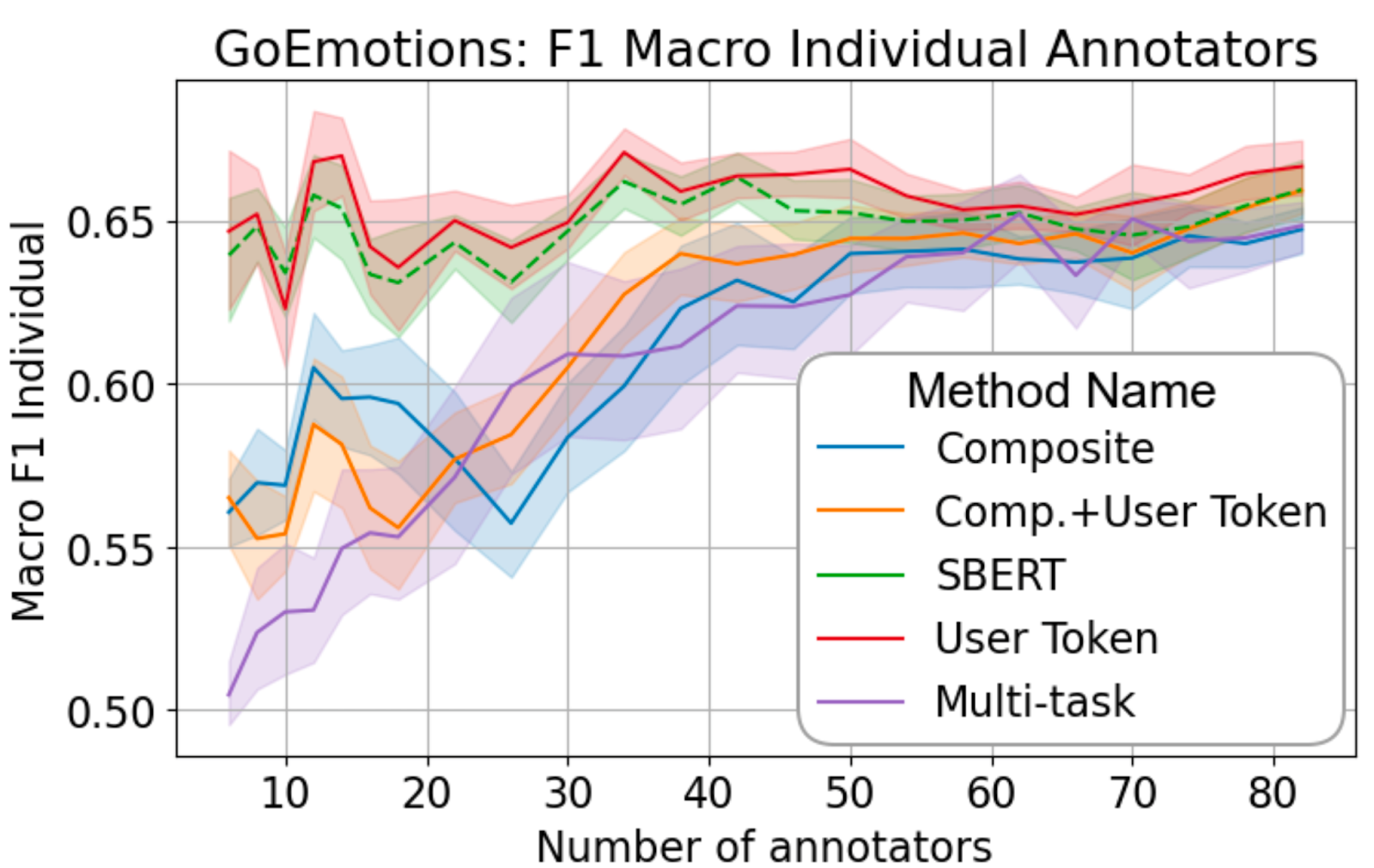
“Corpus Considerations for Annotator Modeling and Scaling (1)”
Authors: Olufunke O.Sarumi, Béla Neuendorf, Joan Plepi, Lucie Flek, Jörg Schlötterer, Charles Welch
Camera-Ready: Paper
In this paper, we perform the first systematic study of the scalability of annotator modeling methods and the relationship between annotator modeling methods and corpus statistics. This study systematically explores various annotator modeling techniques and compares their performance across seven corpora. From our findings, we show that the commonly used user token model consistently outperforms more complex models. We introduce a composite embedding approach and show distinct differences in which model performs best as a function of the agreement with a given dataset. Our findings shed light on the relationship between corpus statistics and annotator modeling performance, which informs future work on corpus construction and perspectivist NLP.
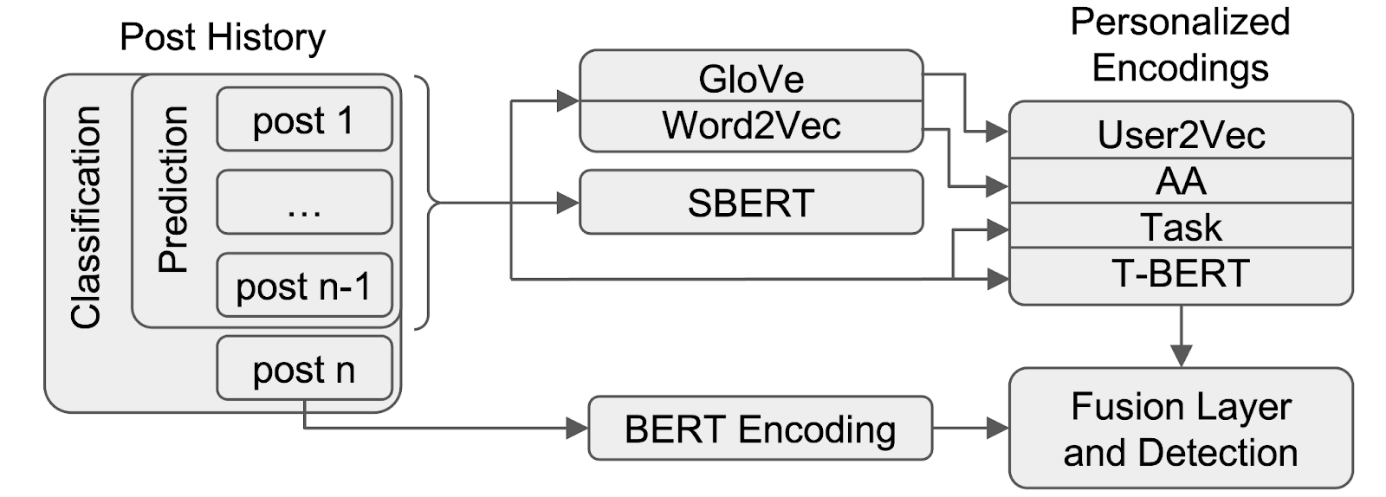
“Harnessing Personalization Methods to Identify and Predict Unreliable Information Spreader Behavior (3)”
Authors: Shaina Ashraf, Fabio Gruschka, Lucie Flek, Charles Welch
Camera-Ready: Paper
In this work, we show that unreliable news can be more accurately detected when using personalization. We present approaches to represent social media users in order to improve performance on three tasks: (1) classification of unreliable news posts, (2) classification of unreliable news spreaders, and, (3) prediction of the spread of unreliable news. We compare the User2Vec method from previous work to two other approaches; a learnable user embedding layer trained with the downstream task, and a representation derived from an authorship attribution classifier. We demonstrate that the implemented strategies substantially improve classification performance over state-of-the-art and provide initial results on the task of unreliable news prediction. Our results indicated that the combination of User2Vec, Task Embeddings, and Authorship Attribution embeddings outperformed individual methods, highlighting the value of integrating multiple user representation techniques.
Prof. Dr. Lucie Flek and Shaina Ashraf contributed to this article.